Learning-Deep-Learning
TiDAR: Think in Diffusion, Talk in Autoregression
January 2026
tl;dr: Self-sepeculative decoding, train in AR + augment with diffusion + deploy as hybrid.
Overall impression
Note: TiDAR is actually NOT a diffusion model at all, but an multitoken prediction autoregressive model. The paper confuses diffusion with MTP AR.
Uses the general idea of specdec, but the draft model is a diffusion model version of the AR base model.
In the same forward pass, TiDAR can do AR check (verification of the last block) and diffusion drafting of next block. Both verification and diffuison geenration can be in parallel.
Key insight: we are NOT using up all the GPU as we are compute bound.
Key ideas
- The sequence has prefix, draft and pre-draft.
- Context ABC, generated DEF
- Proposal 1: ABC + DEF (accepted draft) + GHI (generated pre-draft)
- Proposal 2: ABC + DE (accepted draft) + FGH (generated pre-draft)
- Proposal 3: ABC + D (accepted draft) + EFG (generated pre-draft)
- No matter how many tokens are accepted in verification, we will always have a ready-made draft for the next phase.
- Specially designed structured attention mask for traning and inference
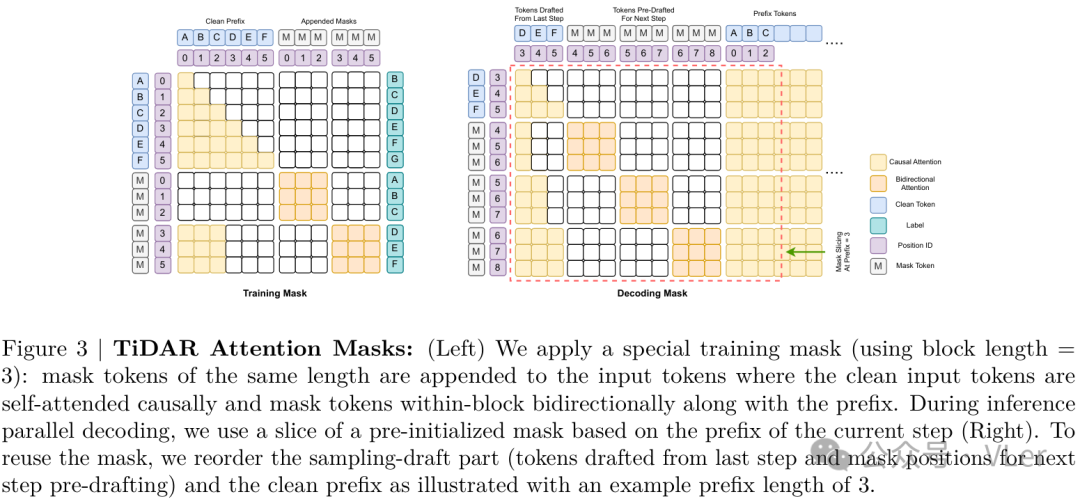
- Same model is used to decode in both diffusion and also AR.
- This may degrade the model’s AR performance a bit.
- In TiDAR, the speedup relies on a single model doing both AR and diffusion in the same forward pass.
Technical details
- AR models are slow to train as well (process multiple toekns but then train one token, NTP)
- The sampling processed in DLM is not causal, and the sampling happens in parallels based on the marginal distributions only. The lack of interaction explains the performance degradation.
- Diffusion is faster but samples from marginial distribution and thus effect is degraded.
- Speculative decoding: verification is easier than generation. Verification can be done in parallel.
Notes
- Review by Yannic Kilcher
- Serious Restriction on Attention Patterns mentioned by Yannic
- Causal attention seriously restricts what is theoretically possible in terms of attention patterns, as tokens are only allowed to look backward in the sequence.
- This restriction applies even during intermediate processing stages.
- It’s a significant trade-off made to enable more effective training and parallelization.
- This is contrasted with how a human might analyze text, where attention can “jump around wildly” before producing the next token.