Learning-Deep-Learning
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
December 2020
tl;dr: Pattern based fine-grained pruning method and use compiler to speed up inference again.
Overall impression
Current pruning methods exhibits two extremes in the design space.
- Non-structured pruning is fine-grained, accurate, but not hardware friendly;
- Structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss.
PatDNN introduces a new dimension in design space: fine-grained pruning patterns (thus PatDNN) inside coarse-grained structures. The direct output is still unstructured and does not lend to speedup in HW. Then compiler is used to reorder kernels and compress weight storage and convert the unstructured network to a structured one that is more suitable for HW acceleration.
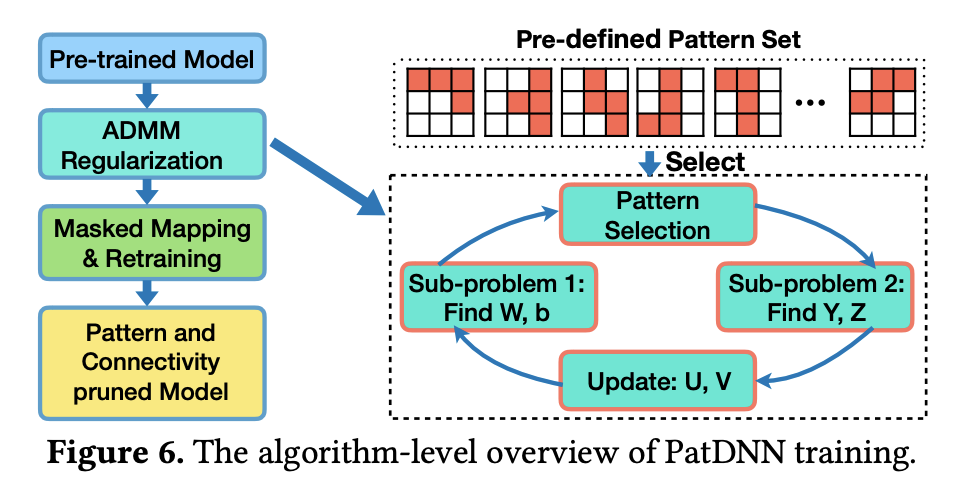

Key ideas
- Summaries of the key ideas
Technical details
- Summary of technical details