Learning-Deep-Learning
MobileNetV2: Inverted Residuals and Linear Bottlenecks (MobileNets v2)
April 2019
tl;dr: Added linear bottleneck layer to MobileNets module. This adds to the computation per module but requires fewer layers to achieve the same performance, thus saving computation.
Overall impression
The authors provided some intuition behind MobileNetsV2, but the paper is really hard to comprehend. Good thing is that the implementation of MobileNetsV2 builds upon and requires only slight change from MobileNetsV1.
Key ideas
- ReLU squashes aways too much information if the features are already in low dimension (Fig. 1 illustrated this perfectly)
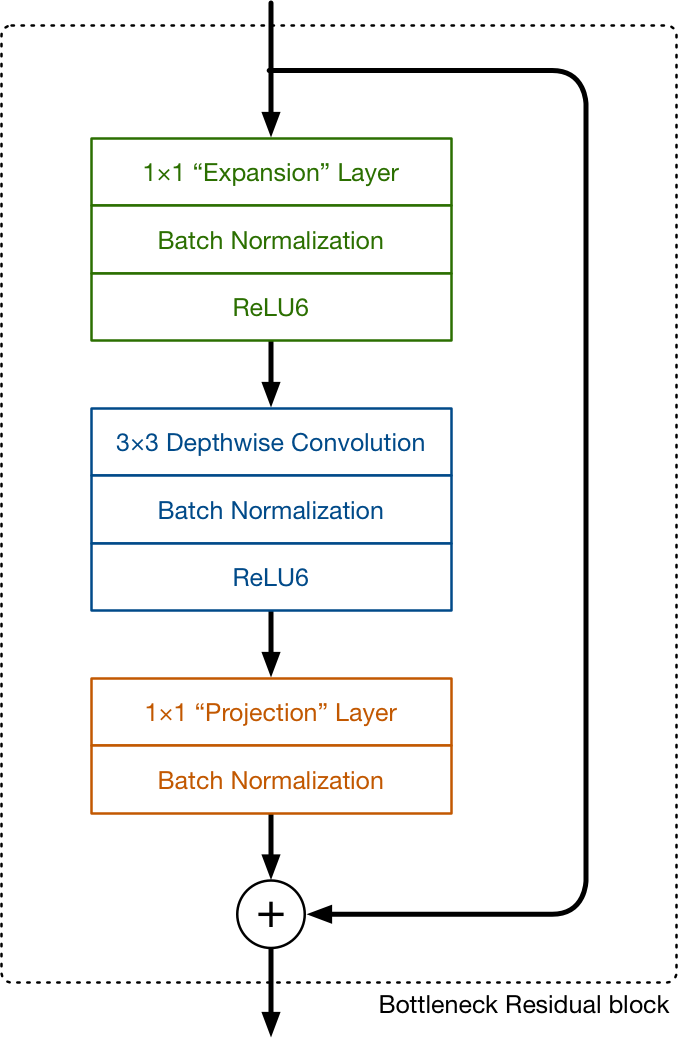
- Linear bottleneck is first used to expand the channel dimension and embed the low dim features into a higher dim (expansion factor t=6)
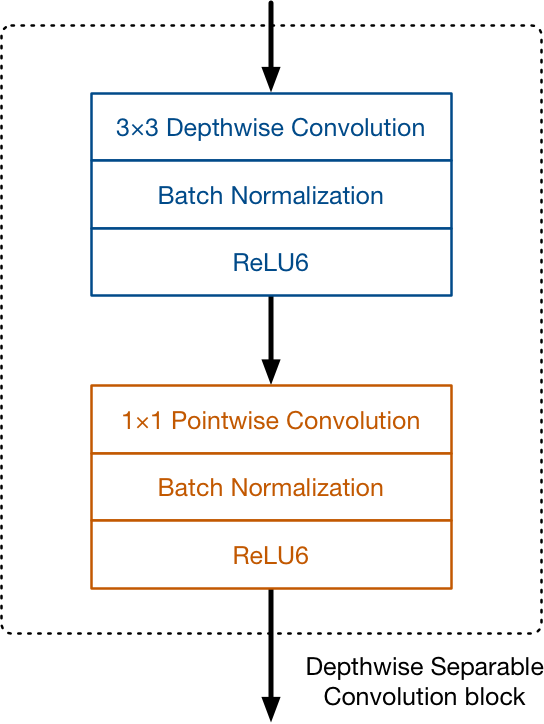
- Depthwise separable convolution is used to “trim down” or “prune” the redundant information
- Inverted residual block reduces memory requirement compared to classical residual block in that it connects the bottlenecks. The total amount of memory required would be dominated by the size of the bottleneck tensors. This is specific to depthwise separable convolution.
- Difference with V1:
- 1x1 convolution in V1 keeps or doubles channel, but in V2 there are two such layers. The first one is the expansion layer. The second one is the projection layer, or bottleneck layer.
- V2 has inverted residual block
- MobileNetV2 can be also used to perform object detection and semantic segmentation. SSDLite may be of interest to autonomous driving.
Technical details
- ReLU6 is essentially a piecewise sigmoid-like activation function with maximum value clipped at 6.
- For depthwise separable convolution, each of the intermediate tensors can be expressed as the concatenation of all the channels, as the inner transformation is per channel. This allows us to reduce the memory requirement to hold only one channel. For most traditional NN, inverted residual block would not produce a significant improvement.
- In practice, replacing a matrix multiplication with several smaller ones hurts performance, so using a block number of 2 to 5 can significantly reduce the memory footprint while maintaining the speed.
- Comparison between V1 and V2:
V1
V2
<img src=https://machinethink.net/images/mobilenet-v2/ExpandProject@2x.png alt=”alt text” height=”100”>
Notes
- Multiple accumulate operation (MAC) vs FLOP: they are different but they are related. On devices that support fused multiply-add, one MAC is one FLOP, otherwise it is two FLOP.
- How to calculate the parameters and FLOPs
- This is a nice blog on MobileNetV1 and MobileNetV2.